 ← Blog
← Blog
Turbocharge HTTP requests in Ruby
- HTTP
- Performance
- Ruby
The problem
The slowest part in many applications is I/O, especially network I/O. We spend a lot of time trying to make sure we reduce the number of calls and cache results of API calls to 3rd party services and resources.
Imagine we want to get data from Rick and Morty API. In this article, we are going to speed up subsequent requests to this API by almost 4x times.
The solution
And yet there’s a trick that even very senior developers and popular API library/clients forget about that can shave off precious time of your network calls built right into HTTP.
Establishing an HTTP connection is very costly, especially if it uses TLS. This is a fixed price added to your HTTP calls that can be avoided by using keep-alive - a mechanism built into HTTP.
According to Wiki:
HTTP keep-alive, or HTTP connection reuse, is the idea of using a single TCP connection to send and receive multiple HTTP requests/responses, as opposed to opening a new connection for every single request/response pair.
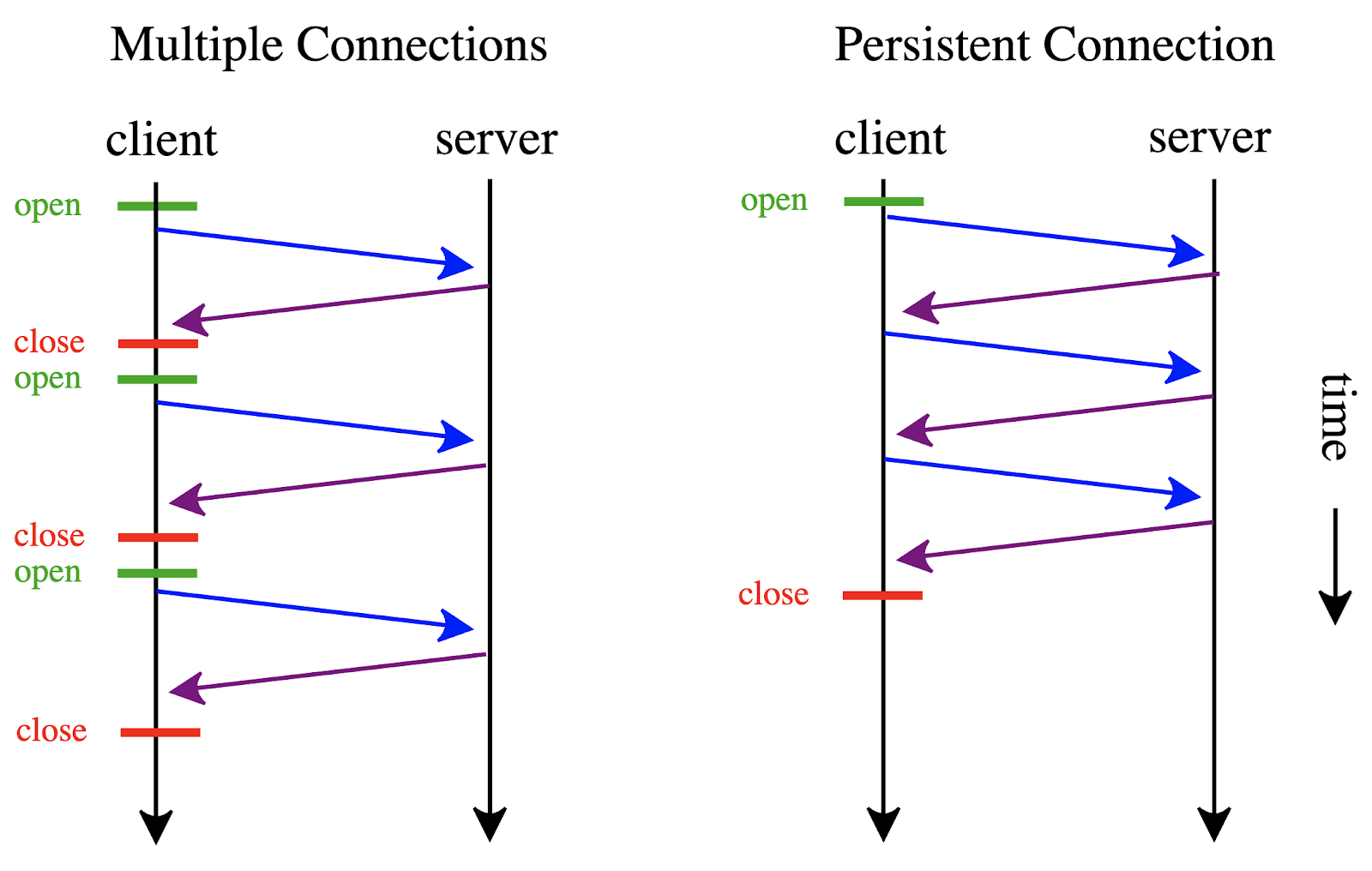
Desired usage
We want our solution to resemble Ruby’s standard library as much as possible, namely Net::HTTP.
Using Ruby’s standard library we could use:
uri = URI("http://example.com")
http = Net::HTTP.new(uri.host, uri.port)
request = Net::HTTP::Get.new(uri.request_uri)
response = http.request(request)Our PersistentHttpClient usage would look like that:
uri = URI("http://example.com")
http = PersistentHttpClient.get(uri)
request = Net::HTTP::Get.new(uri.request_uri)
response = http.request(request)Implementation
class PersistentHttpClient
DEFAULT_OPTIONS = { read_timeout: 80, open_timeout: 30 }.freeze
class << self
# url: URI / String
# options: any options that Net::HTTP.new accepts
def get(url, options = {})
uri = url.is_a?(URI) ? url : URI(url)
connection_manager.get_client(uri, options)
end
private
# each thread gets its own connection manager
def connection_manager
# before getting a connection manager
# we first clear all old ones
remove_old_managers
Thread.current[:http_connection_manager] ||= new_manager
end
def new_manager
# create a new connection manager in a thread safe way
mutex.synchronize do
manager = ConnectionManager.new
connection_managers << manager
manager
end
end
def remove_old_managers
mutex.synchronize do
removed = connection_managers.reject!(&:stale?)
(removed || []).each(&:close_connections!)
end
end
# mutex isn't needed for CRuby, but might be needed
# for other Ruby implementations
def mutex
@mutex ||= Mutex.new
end
def connection_managers
@connection_managers ||= []
end
end
# connection manager represents
# a cache of all keep-alive connections
# in a current thread
class ConnectionManager
# if a client wasn't used within this time range
# it gets removed from the cache and the connection closed.
# This helps to make sure there are no memory leaks.
STALE_AFTER = 5.minutes
# Seconds to reuse the connection of the previous request. If the idle time is less than this Keep-Alive Timeout, Net::HTTP reuses the TCP/IP socket used by the previous communication. Source: Ruby docs
KEEP_ALIVE_TIMEOUT = 30 # seconds
# KEEP_ALIVE_TIMEOUT vs STALE_AFTER
# STALE_AFTER - how long an Net::HTTP client object is cached in ruby
# KEEP_ALIVE_TIMEOUT - how long that client keeps TCP/IP socket open.
attr_accessor :clients_store, :last_used
def initialize
self.clients_store = {}
self.last_used = Time.now
end
def get_client(uri, options)
mutex.synchronize do
# refresh the last time a client was used,
# this prevents the client from becoming stale
self.last_used = Time.now
# we use params as a cache key for clients.
# 2 connections to the same host but with different
# options are going to use different HTTP clients
params = [uri.host, uri.port, options]
client = clients_store[params]
return client if client
client = Net::HTTP.new(uri.host, uri.port)
client.keep_alive_timeout = KEEP_ALIVE_TIMEOUT
# set SSL to true if a scheme is https
client.use_ssl = uri.scheme == "https"
# dynamically set Net::HTTP options
(DEFAULT_OPTIONS.merge(options)).each_pair do |key, value|
client.public_send("#{key}=", value)
end
# open connection
client.start
# cache the client
clients_store[params] = client
client
end
end
# close connections for each client
def close_connections!
mutex.synchronize do
clients_store.values.each(&:finish)
self.clients_store = {}
end
end
def stale?
Time.now - last_used > STALE_AFTER
end
def mutex
@mutex ||= Mutex.new
end
end
endBenchmarks
require 'benchmark'
n = 100
def random_uri
URI("https://rickandmortyapi.com/api/character/#{rand(399) + 1}")
end
Benchmark.bm do |x|
x.report do
n.times do
uri = random_uri
http = Net::HTTP.new(uri.host, uri.port)
http.use_ssl = true
request = Net::HTTP::Get.new(uri.request_uri)
response = http.request(request)
response_code = response.code.to_i
raise response_code unless response_code == 200
end
end
x.report do
n.times do
uri = random_uri
http = PersistentHttpClient.get(uri)
request = Net::HTTP::Get.new(uri.request_uri)
response = http.request(request)
response_code = response.code.to_i
raise response_code unless response_code == 200
end
end
end
# user system total real
# 0.354217 0.098482 0.452699 ( 89.936997)
# 0.064028 0.011415 0.075443 ( 23.040262)As we can see, for this simple HTTP call the speed gain is a whopping 3.9x!
Of course, for API calls where a server takes longer to process a request the gain won’t be as big, but for simple calls, the difference can’t be ignored.
The advantage of this approach in comparison to something like github.com/drbrain/net-http-persistent is that the solution in this article doesn’t keep connections open indefinitely to drain resources and have memory leaks. Also, it automatically manages a cache of clients instead of you having to deal with that ad hoc.
It’s important to remember that the keep-alive timeout that you set on the Ruby side must be respected by the server that receives it, some servers may choose to close a connection despite this setting.
What’s on the server?
I think it’s also important to mention, that while keep-alive connections provide utility to clients, they can potentially overload your servers if not configured properly. Misbehaving clients can hog your memory, thus it’s important to place your precious application servers behind a reverse proxy such as Nginx.
Thank you for reading!